Notes on iTransformer
February 2, 2024
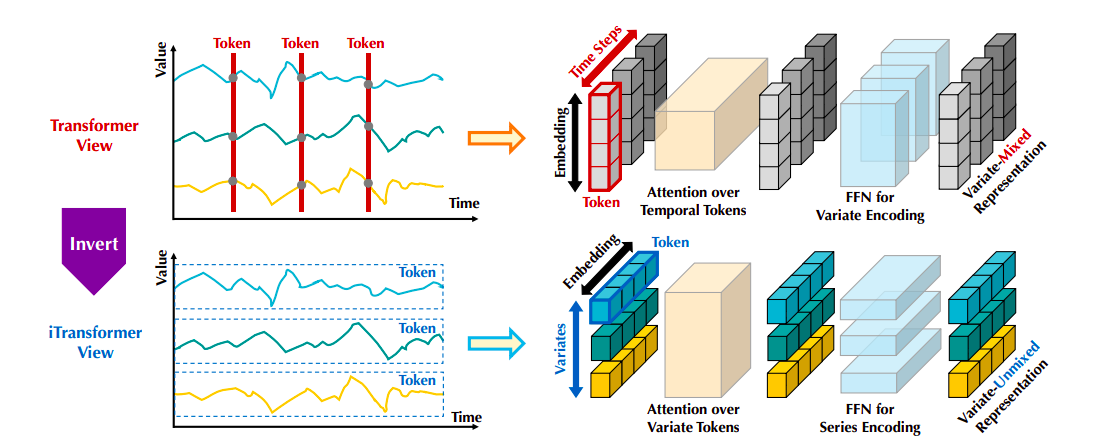
iTransformer: Inverted Transformers are Effective for Time Series Forecasting
Motivation
- Transformer-based forecasts are less performant and less efficient than simple linear layers.
- In particular, although temporal tokens capture temporal dependencies, in the case of a multivariate time series, a single token does not capture correlations between the variates at a same time point.
- The receptive field of the token formed by a single time step is excessively local. Note: receptive field is sort of an input capacity that affects the features. In this case, we are being implied that the temporal token can capture more local information.
- There is a growing emphasis on ensuring the independence of variates and utlizing mutual information (as defined in information theory), especially in modelling multivariate correlation.
- In sum, the temporal token structure of Transformer is not bad, but can be modified to increase its capacity.
Main idea
- We have a time series that holds multiple variates at each time point. Instead of embedding variates at the same time point together, the idea is to for each variate, embed its whole time series together.
- This inversion is said to give a more variate-centric and a better-levaraged representation.
Paper notation
where
- is the number of variates;
- is the time steps; and
- is the future time steps.
Structure Overview
Same structure as the encoder of Transformer.
where the main block is repeated times as denoted in the paper.
- Self-attention reveal more multivariate correlations.
- Feed forward network give a series representation.
- Layer normalization reduce discrepancies among variates.
- Focus on representation learning and adaptive correlating of multivariate series.
Independent tokenization of the time series is claimed to describe properties of the variates.
Prediction is formulated as
where
- contained embedded tokens of dimension and the superscript denotes the layer index.
- and are implemented with a multi-layer perceptron.
- denotes the multivariate attention, layer normalization, FFN, layer normalization block.
As the order of sequence is implicitly stored in the neuron permutation of the feed-forward network, the position embedding in the vanilla Transformer is no longer needed here.